Machine learning is one of the strategies many companies are using as they try to improve and differentiate their product by augmenting the user’s experience. Building artificial intelligence into apps can improve what can be done for customers and users, but can also affect how customers and users interact with the machine. In this article I am covering how, as the designer, specific issues for you to look out for when testing user scenarios, preparing for doing user testing, and doing user testing. I’ve previously covered how choosing an algorithm affects the user’s experience where I cover the research that is needed before design begins. The information from the previous article will help when doing user testing too.
PROTOTYPE TESTING & VERIFICATION
Even before doing user testing you want to make sure all of the algorithms are working. If you can hand off UX requirements to the QA testing group it’s helpful. But, I’ve found a lot of the time the QA group is also adjusting to the new reality of working with AI; and a lot of the time, as long as they can verify that the app gives a reasonable response, it passes. However, AI can give many responses that make sense but do not help the user to achieve their goals.
So is the AI helping? I’ve found the easiest way to find out is an A/B test of AI vs no AI. The problem is that once software has been written it is hard to disable the AI and have the software still work. A good way around this is to have the developers set up an alternative algorithm to just take all the data and find the mean average. If the AI can not preform better to achieve the stated goals than averaged data then back to the drawing board before user testing.
USER TESTING
As soon as there is anything usable for the AI it is best to test with the users to verify what it is giving what is important to them. Even after choosing a specific algorithm developers can modify the algorithm using human imposed variables called Hyper-parameters. These settings can tweak how the machine learning algorithm preforms. It can be things like how many layers of neurons, or the number of neurons in a layer. The important thing to remember is that the more accuracy achieved is usually associated with higher processor requirements.
So what problems can you discover? Let’s start with an example that during user testing you all the users getting too similar of recommendations from the AI or the AI is always making guesses that are too similar to each other. This could be caused by Underfitting. The best way to explain underfitting is with an X-Y graph. In this example we are only using two lists of measurements/data called Features. Of course what you are working on will have more features, but the idea is the same. Figure 1 shows the hypothetical AI giving a perfect recommendation line ignoring all noise.
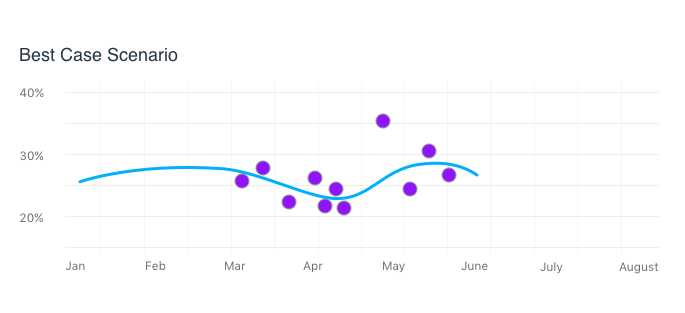
Underfitting is ignoring or generalizing too much data during training. It is treating everything as noise.
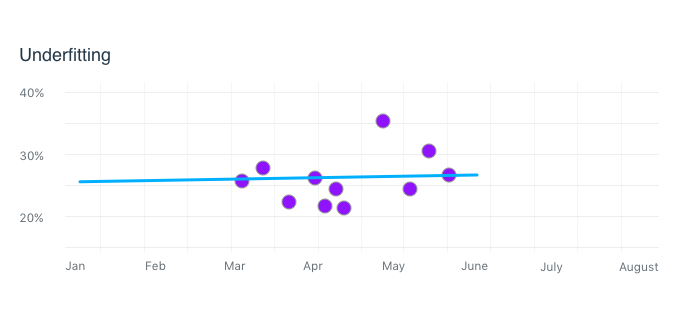
The solution is to train on more data (or data closer to what the users are using), add more features (measure more things), create a more more complex model (add more neurons or layers to the model). Developers will have to know which hyperparameters make the most sense to change in your situation; and there is a good chance they will change all of them to see which ones create the best results. Your part is knowing this can be a problem, so you can tell them where 1) the data needs to be sampled, 2) and where the answers needs to be right.
The opposite problem is Overfitting. This is trying to fit every point on the graph. The algorithm will work great when all the points are part of the training data but the AI can’t generalize when it sees something new. This can happen when no Cross-validation is done (Splitting out some data to test the AI on instead of using it all for training.) Sometimes cross-validation can’t be done, but sometimes it is forgotten on the list of things to do.
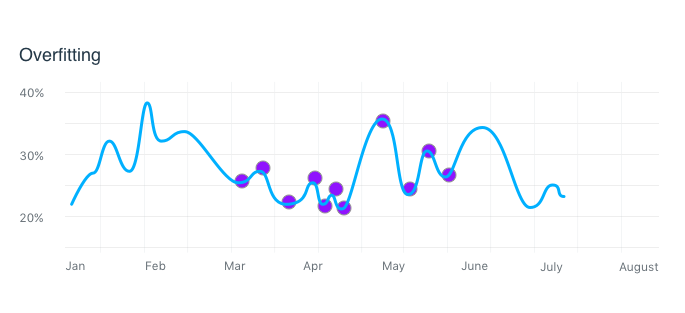
Overfitting shows up during user testing as the edge cases being wildly off, so there is actually a better chance of catching it when validating the prototype. Of course there are the basic remedies of removing layers or neurons but another solution is something called regularization.
Regularization is a fix for the problem machine learning has if some of the features are small numbers and some are large. The algorithm will tend to forget the small numbers. For example, in a home buying AI with the features as number of rooms and price, since the price is much higher, the number of rooms won’t matter. The fix is to make all the data sets look similar. For example make the price of the homes in 100k (eg. $2.1 instead of $210,000). For natural language processing regularization will strip off all of the verb endings so working, worked, and work all count as the same word.
Usually regularization works without your intervention unless the thing the user is interested in relates to something that was regularized away. While this can pop up in user testing it is easier to catch by talking with the developers to see what data they have regularized and make sure it does not conflict with the users goals.
DETECTING BIAS
Bias is a big enough problem it needs its own section. As smart as machine learning gets, when a bias is detected it can remind you just how dumb AI still is. First, I will cover Statistical bias. This is when the “bias” is part of the error term. Basically the model is not being the true model. So if the model is off this is something that should be designed out, hopefully with your help the developers never see this problem. Using the user stories and goals take into account the variance and bias from reality. Variance is how far from the average numbers can get. Think of a shotgun pattern on a wall. The further back you stand when shooting the gun the more the dots will be spread out, or the higher the variance. The tolerance for a high or low variance depends on what the user goals are.
Also know that variance interacts with bias. If variance is how spread out the answers are, bias is how far off the center of the target is. So based on what the user goals are (like consistency is more important than accuracy), you might want a high bias and a low variance. This would make all the answers close together with a predictable distance from reality.
The second type of bias is biased training data. Biased training data is when there is a problem with how the data is gathered. Discovering the AI being effected by training data was first detected in 1964 ( with what might be apocryphal) when they were trying to use an AI to detect tanks in images. Testing off the training data went well but it could not work with new photos. It turns out all of the tank photos were from sunny days and non-tank photos on cloudy days. So the AI was good at detecting the weather in the photo instead of finding tanks.
Another example is using an AI to decide who to keep in the hospital with extra care and who to send home. The AI kept recommending people with asthma to be sent home which went against obvious medical knowledge. It turns out people with asthma were getting extra attention from the doctors because of the extra risk. this extra attention was not factored into the training data and therefore leading the AI to the bias not matching reality.
Detecting biased training data is something you will need to look for on both ends. During the design phase sit down with the developers to make sure the training data parallels the user goals, actions, and stories. Also make sure the training and testing data are split randomly. For example you don’t want stock market data to be trained with all the data from last year and tested in the data from the last two weeks.
Once the algorithm is ready make sure you are covering all of your persona types when doing your user testing. Also, this is a good place to find the subject matter experts (SMEs) and go through heuristic evaluations with them. Like the doctors in the previous example they can say when recommendations do not match up with reality.
A subcategory of biased training data is data normalization. As you know, users will put in fake data if there is forced collection to reach their goal. A good example is known as the Schenectady problem. There is a zip code 12345. It is for the GE factory in Schenectady, New York. If you try to use unnormalized data the amount of people showing up as living inside of a factory will be unusually high. Other anomalies include the number of people sharing the birthday January 1, 1900 and phone numbers that start with 555. It is easier to design in catch questions for user surveys. But, if you are working with already collected data the algorithms used to normalize data differs on what you are working on so the main things to verify is 1) the data is normalized before AI training and 2) that if your user groups and personas do have “out of the norm” peculiarities that they are not normalized away out of the data.
The last type of bias to cover is social bias. This is when you know the data goes against the company values. All data collected is from the past and from people who are acting on what they learned in the past. So things like racism and bigotry will show up in real data sets and need to be adjusted for. The biggest problem is remembering there is a problem since most development is done within one bubble or other. As the designer it is something to check for: 1) during design, 2) verifying in the training and testing data, 3) making sure the personas cover race, culture, personal and group identity, and gender and 4) to test against those persona groups.
Social bias gets split up into two groups (and I’m quoting directly from Kate Crawford, NIPS 2018) Harms of allocation covers discrimination in the product or service, for example approving a mortgage, granting a parole, or deciding insurance rates. The second is Harms of representation. This covers the social inequalities and stereotypes we don’t want to perpetuate.
There are plenty of examples of companies getting embarrassed by this. With Google, being a leader in machine learning, run into this problem a lot. There was the time their image recognition app was recognizing black people and tagging them as gorillas. The problem was there was not enough racial diversity in the developers working on the project so when they were testing with their own pictures they never saw the problem (causing biased training data).
Google also had a problem with their search recommendations. Since they build up their recommendation lists based on what other people typed in; when searching, racist recommendations used to pop-up when minorities were words used. They fixed this by being aware of the problem, detecting the racist searches, moving them to a different list than the training data so when racist data shows up as part of the test data it can still be acknowledged but will not count against the accuracy of the algorithm and will not show up as a suggestion.
Other examples include the profiling algorithm being less likely to recommend high paying jobs to women (story by Prachi Patel) and searching for historically black names are more likely to show ads for prison background checks (research by L. Sweeney). Or, when doing language translation, translating from non gendered sentences for doctor and nurse will add male to doctor and female to nurse. Even the tools used by developers like word2vec (a tool to categorize words to other words they are most likely to be used with)is more likely to associate male associated words with brilliant, genius. commit, and firepower, while female associated words are near babe, sassy, sewing, and homemaker.
CONCLUSION
This is just scratching the surface of problems you can run into. There are so many different areas of AI I can only cover some of them. Not to mention everyone is working on a customized version of an algorithm to get it to work for their own specific needs. If you come across a design problem or solution with AI, you are free to contact me and let me know so I can help or get to word out about good solutions.
Recent Comments